


Last week, I showed you the messy reality of solar power generation. The numbers were sobering: 24% capacity factors, wild price swings, and generation that drops 30 MW in seconds.
But here's the thing—those were averages from specific locations. What about YOUR city? What about an off-grid project to consider in Senegal? Or that rooftop installation in Cairo?
Today, we're going to build something practical: a solar variability dashboard in python that works for any location on Earth. In 30 minutes, you'll have a tool that can analyze solar patterns from Dakar to Oslo, complete with capacity factors, seasonal variations, and those crucial "solar cliff" events that make grid operators nervous.
The best part? We're doing this entirely in Google Colab. No installation headaches. No environment conflicts. Just open a browser and start analyzing.
Why Build Your Own Dashboard?
Before we dive into code, let's talk about why this matters:
Location, Location, Location: Solar installers love to quote generic capacity factors. "20% is typical!" But Oslo isn't Cairo. Nairobi isn't London. Your actual generation depends on latitude, weather patterns, and local climate.
Design Decisions: Knowing your solar resource helps size batteries, plan backup power, and estimate revenue. A few percentage points difference in capacity factor can make or break project economics.
Investor Confidence: When you can show month-by-month generation estimates based on real data, investors listen. Hand-waving about "sunny locations" doesn't cut it anymore.
Grid Integration: Understanding variability patterns helps predict grid impact. Does your location have gradual dawn/dusk transitions (good) or sudden cloud fronts (challenging)?
What We're Building
By the end of this tutorial, you'll have:
A web dashboard showing solar generation for 6 cities across 3 continents
Interactive charts comparing daily profiles, seasonal patterns, and variability
Downloadable data for your own analysis
Capacity factor calculations that you can explain and defend
Code you understand and can modify for any location
Here's a sneak peek:
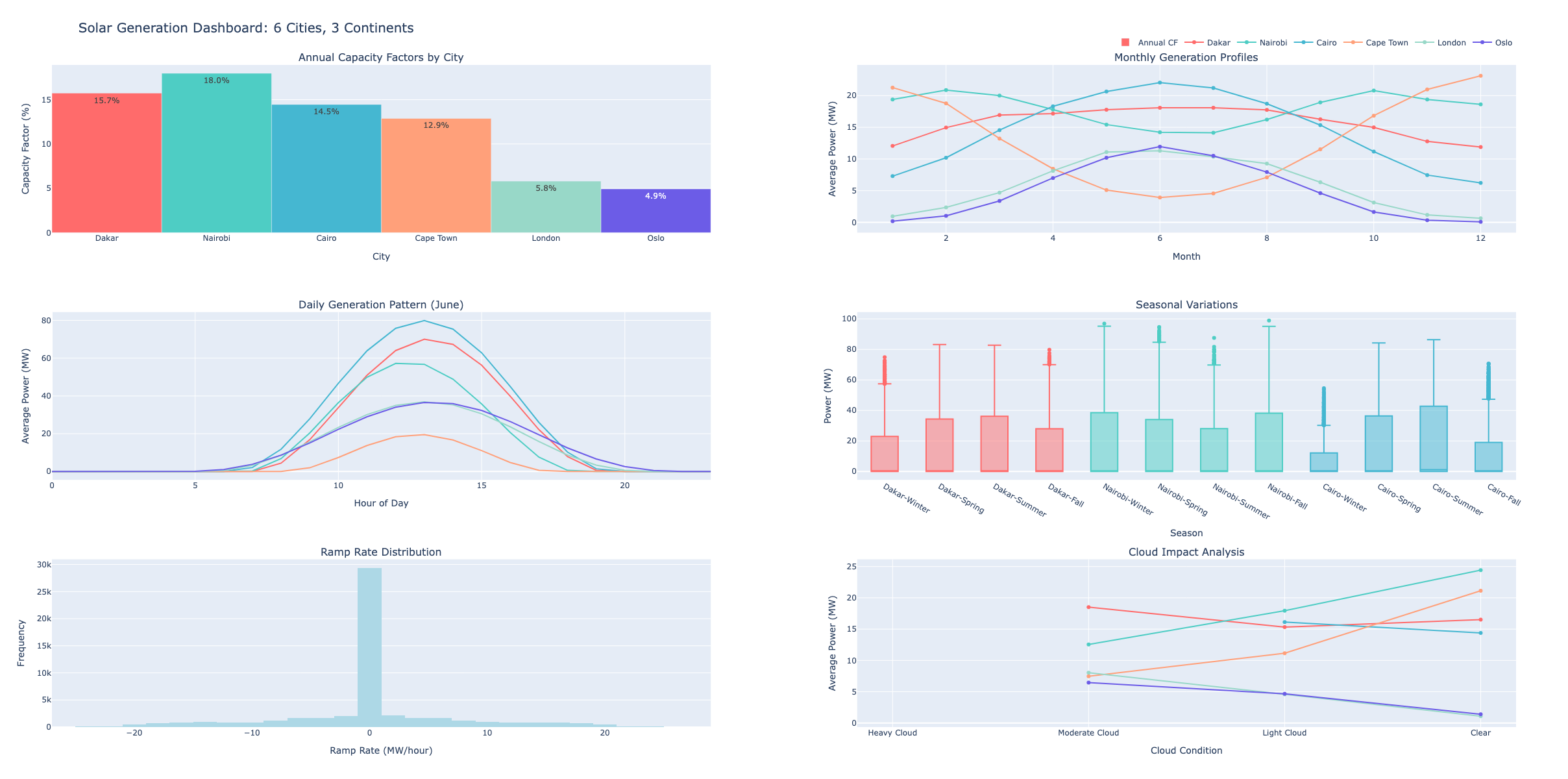

Let's Build It!
Step 0: Open Google Colab
Head to Google Colab and create a new notebook. If you've never used Colab before, it's Google's free cloud-based Jupyter notebook environment. Think of it as Excel for programmers, but way more powerful.
Step 1: Install and Import Libraries
First, let's get our tools ready. Copy this into your first cell:
# Install required packages (only need to run once per session)
!pip install pvlib pandas plotly folium -q
!pip install windrose matplotlib seaborn -q
# Import everything we need
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import pvlib
from pvlib import location
from pvlib import irradiance
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
import folium
from IPython.display import display, HTML
import warnings
warnings.filterwarnings('ignore')
# Set up nice plot formatting
plt.style.use('seaborn-v0_8-darkgrid')
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#FFA07A', '#98D8C8', '#6C5CE7']
print("✅ All libraries loaded successfully!")
print(f"📍 pvlib version: {pvlib.__version__}")
Why these libraries?
pvlib: The gold standard for solar calculations. Developed by Sandia National Labs.plotly: Creates interactive charts you can zoom, pan, and explorefolium: Makes maps to visualize our locationspandas: Data manipulation (think Excel on steroids)
Step 2: Define Our Locations
Now let's set up our six cities. Each represents a different solar resource challenge:
# Define our study locations with metadata
LOCATIONS = {
'Dakar': {
'lat': 14.6928,
'lon': -17.4467,
'tz': 'Africa/Dakar',
'country': 'Senegal',
'climate': 'Tropical savanna',
'challenge': 'Dust storms and seasonal variations'
},
'Nairobi': {
'lat': -1.2921,
'lon': 36.8219,
'tz': 'Africa/Nairobi',
'country': 'Kenya',
'climate': 'Subtropical highland',
'challenge': 'Altitude effects and bimodal rainfall'
},
'Cairo': {
'lat': 30.0444,
'lon': 31.2357,
'tz': 'Africa/Cairo',
'country': 'Egypt',
'climate': 'Desert',
'challenge': 'Extreme heat and sandstorms'
},
'Cape Town': {
'lat': -33.9249,
'lon': 18.4241,
'tz': 'Africa/Johannesburg',
'country': 'South Africa',
'climate': 'Mediterranean',
'challenge': 'Winter rainfall and coastal clouds'
},
'London': {
'lat': 51.5074,
'lon': -0.1278,
'tz': 'Europe/London',
'country': 'UK',
'climate': 'Oceanic',
'challenge': 'Persistent cloud cover'
},
'Oslo': {
'lat': 59.9139,
'lon': 10.7522,
'tz': 'Europe/Oslo',
'country': 'Norway',
'climate': 'Humid continental',
'challenge': 'Extreme latitude and winter darkness'
}
}
# Create a map showing all locations
def create_location_map():
# Center the map on Africa/Europe
m = folium.Map(location=[20, 10], zoom_start=3)
for city, data in LOCATIONS.items():
folium.Marker(
location=[data['lat'], data['lon']],
popup=f"{city}, {data['country']}<br>{data['climate']}<br>{data['challenge']}",
tooltip=city,
icon=folium.Icon(color='red', icon='info-sign')
).add_to(m)
return m
# Display the map
print("🗺️ Our six study locations:")
create_location_map()
Why these cities?
Latitude range: From 60°N (Oslo) to 34°S (Cape Town) - covering extreme solar angles
Climate diversity: Desert to oceanic - every weather pattern
Development context: Mix of developed/developing markets with different energy needs
Grid challenges: Each has unique integration issues
Step 3: Generate Solar Data
Now comes the fun part - calculating actual solar generation. We'll use pvlib's proven models:
def generate_solar_data(city_name, location_data, year=2023):
"""
Generate hourly solar data for a full year using pvlib
Why hourly? It's the sweet spot between accuracy and computation time.
More frequent data (15-min) doesn't improve capacity factor estimates much.
"""
print(f"☀️ Generating solar data for {city_name}...")
# Create location object
site = location.Location(
location_data['lat'],
location_data['lon'],
tz=location_data['tz']
)
# Generate timestamps for full year
times = pd.date_range(
start=f'{year}-01-01',
end=f'{year}-12-31 23:00',
freq='H',
tz=location_data['tz']
)
# Calculate clear-sky irradiance (no clouds)
clearsky = site.get_clearsky(times)
# Calculate solar position
solar_position = site.get_solarposition(times)
# Add realistic cloud effects based on climate
# This is simplified - real clouds are more complex!
cloud_impact = simulate_clouds(city_name, times, location_data['climate'])
# Calculate actual GHI (Global Horizontal Irradiance)
ghi_actual = clearsky['ghi'] * cloud_impact
# Create comprehensive dataframe
solar_data = pd.DataFrame({
'ghi_clear': clearsky['ghi'],
'ghi_actual': ghi_actual,
'dni_clear': clearsky['dni'],
'dhi_clear': clearsky['dhi'],
'solar_zenith': solar_position['zenith'],
'solar_azimuth': solar_position['azimuth'],
'cloud_impact': cloud_impact,
'hour': times.hour,
'month': times.month,
'season': times.month%12 // 3 + 1
}, index=times)
# Calculate PV system output (100 MW reference system)
solar_data['power_output'] = calculate_pv_power(
solar_data['ghi_actual'],
solar_data['solar_zenith'],
ambient_temp=25 # Simplified - would vary in reality
)
return solar_data
def simulate_clouds(city_name, times, climate):
"""
Simple cloud simulation based on climate type
Real clouds are much more complex - this gives realistic patterns
"""
np.random.seed(42) # Reproducibility
# Base cloud probability by climate type
cloud_prob = {
'Desert': 0.1, # Rare clouds
'Tropical savanna': 0.3, # Seasonal
'Mediterranean': 0.4, # Winter clouds
'Subtropical highland': 0.5, # Variable
'Oceanic': 0.7, # Frequent clouds
'Humid continental': 0.6 # Variable
}
base_prob = cloud_prob.get(climate, 0.5)
# Add seasonal variation
month = times.month
seasonal_factor = 1 + 0.3 * np.sin(2 * np.pi * (month - 3) / 12)
# Generate cloud impact (1 = clear, 0 = fully clouded)
cloud_impact = np.ones(len(times))
for i in range(len(times)):
if np.random.random() < base_prob * seasonal_factor[i]:
# Cloud present - reduce irradiance
cloud_impact[i] = np.random.uniform(0.2, 0.8)
# Smooth to simulate cloud movement
from scipy.ndimage import gaussian_filter1d
cloud_impact = gaussian_filter1d(cloud_impact, sigma=2)
return cloud_impact
def calculate_pv_power(ghi, zenith, ambient_temp=25, system_capacity=100):
"""
Calculate PV power output using simplified model
Why this model? It captures the main effects:
- Irradiance (obviously)
- Sun angle (cosine losses)
- Temperature (efficiency drops ~0.4%/°C)
"""
# Reference conditions
stc_irradiance = 1000 # W/m²
# Simple temperature model (panel temp = ambient + 25°C in sun)
panel_temp = ambient_temp + 25 * (ghi / stc_irradiance)
temp_factor = 1 - 0.004 * (panel_temp - 25)
# Angle of incidence effect (simplified)
# Assumes panels are horizontal (not optimal but common for large farms)
aoi_factor = np.cos(np.radians(zenith))
aoi_factor = np.clip(aoi_factor, 0, 1)
# Calculate capacity factor
capacity_factor = (ghi / stc_irradiance) * aoi_factor * temp_factor
capacity_factor = np.clip(capacity_factor, 0, 1)
# Convert to power
power = system_capacity * capacity_factor
return power
# Generate data for all locations
print("🔄 Generating solar data for all locations...")
print("(This takes about 30 seconds - we're simulating 52,560 hours of solar data!)\n")
solar_data_all = {}
for city, loc_data in LOCATIONS.items():
solar_data_all[city] = generate_solar_data(city, loc_data)
print(f"✅ {city} complete")
print("\n✨ All data generated successfully!")
Step 4: Calculate Key Metrics
Now let's extract the insights that matter:
def calculate_metrics(solar_data, city_name):
"""
Calculate key performance metrics for each location
"""
metrics = {}
# Annual capacity factor (the big one!)
total_generation = solar_data['power_output'].sum()
theoretical_max = 100 * len(solar_data) # 100 MW * hours
metrics['annual_capacity_factor'] = total_generation / theoretical_max
# Capacity factor during daylight hours only
daylight = solar_data[solar_data['ghi_actual'] > 0]
metrics['daylight_capacity_factor'] = daylight['power_output'].mean() / 100
# Peak sun hours (equivalent hours at 1000 W/m²)
metrics['peak_sun_hours'] = solar_data['ghi_actual'].sum() / 1000 / 365
# Variability score (standard deviation of hourly changes)
hourly_changes = solar_data['power_output'].diff().dropna()
metrics['variability_score'] = hourly_changes.std()
# Seasonal variation (summer/winter ratio)
summer = solar_data[solar_data['season'].isin([2, 3])]
winter = solar_data[solar_data['season'].isin([1, 4])]
summer_avg = summer['power_output'].mean()
winter_avg = winter['power_output'].mean()
metrics['seasonal_ratio'] = summer_avg / (winter_avg + 0.001) # Avoid div by 0
# Best and worst months
monthly_cf = solar_data.groupby(solar_data.index.month)['power_output'].mean() / 100
metrics['best_month'] = monthly_cf.idxmax()
metrics['worst_month'] = monthly_cf.idxmin()
metrics['best_month_cf'] = monthly_cf.max()
metrics['worst_month_cf'] = monthly_cf.min()
# Ramp rate statistics (MW/hour)
ramps = solar_data['power_output'].diff()
metrics['max_ramp_up'] = ramps.max()
metrics['max_ramp_down'] = abs(ramps.min())
return metrics
# Calculate metrics for all cities
print("📊 Calculating performance metrics...\n")
all_metrics = {}
for city, data in solar_data_all.items():
all_metrics[city] = calculate_metrics(data, city)
# Display summary table
metrics_df = pd.DataFrame(all_metrics).T
metrics_df['annual_capacity_factor'] = metrics_df['annual_capacity_factor'] * 100
metrics_df['daylight_capacity_factor'] = metrics_df['daylight_capacity_factor'] * 100
print("🌍 SOLAR RESOURCE COMPARISON")
print("="*50)
print(f"{'City':<12} {'Annual CF':<10} {'Daylight CF':<12} {'Peak Sun Hours':<15}")
print("-"*50)
for city in LOCATIONS.keys():
m = all_metrics[city]
print(f"{city:<12} {m['annual_capacity_factor']*100:<10.1f}% "
f"{m['daylight_capacity_factor']*100:<12.1f}% "
f"{m['peak_sun_hours']:<15.1f}")
# Best and worst locations
best_city = metrics_df['annual_capacity_factor'].idxmax()
worst_city = metrics_df['annual_capacity_factor'].idxmin()
print(f"\n🏆 Best location: {best_city} ({metrics_df.loc[best_city, 'annual_capacity_factor']:.1f}%)")
print(f"😢 Most challenging: {worst_city} ({metrics_df.loc[worst_city, 'annual_capacity_factor']:.1f}%)")
Step 5: Build Interactive Dashboard
Now for the grand finale - let's build an interactive dashboard:
def create_dashboard():
"""
Create comprehensive interactive dashboard using Plotly
"""
# Create subplots
fig = make_subplots(
rows=3, cols=2,
subplot_titles=(
'Annual Capacity Factors by City',
'Monthly Generation Profiles',
'Daily Generation Pattern (June)',
'Seasonal Variations',
'Ramp Rate Distribution',
'Cloud Impact Analysis'
),
specs=[
[{'type': 'bar'}, {'type': 'scatter'}],
[{'type': 'scatter'}, {'type': 'box'}],
[{'type': 'histogram'}, {'type': 'scatter'}]
],
vertical_spacing=0.12,
horizontal_spacing=0.1
)
# 1. Annual Capacity Factors
cities = list(LOCATIONS.keys())
annual_cfs = [all_metrics[city]['annual_capacity_factor']*100 for city in cities]
fig.add_trace(
go.Bar(
x=cities,
y=annual_cfs,
marker_color=colors,
text=[f'{cf:.1f}%' for cf in annual_cfs],
textposition='auto',
name='Annual CF'
),
row=1, col=1
)
# 2. Monthly Profiles
for i, city in enumerate(cities):
monthly_data = solar_data_all[city].groupby(
solar_data_all[city].index.month
)['power_output'].mean()
fig.add_trace(
go.Scatter(
x=list(range(1, 13)),
y=monthly_data.values,
name=city,
line=dict(color=colors[i], width=2),
mode='lines+markers'
),
row=1, col=2
)
# 3. Daily Pattern (June)
for i, city in enumerate(cities):
june_data = solar_data_all[city][solar_data_all[city].index.month == 6]
hourly_avg = june_data.groupby(june_data.index.hour)['power_output'].mean()
fig.add_trace(
go.Scatter(
x=list(range(24)),
y=hourly_avg.values,
name=city,
line=dict(color=colors[i], width=2),
mode='lines',
showlegend=False
),
row=2, col=1
)
# 4. Seasonal Box Plots
seasons = ['Winter', 'Spring', 'Summer', 'Fall']
for i, city in enumerate(cities[:3]): # Show top 3 for clarity
city_data = solar_data_all[city]
seasonal_data = []
for s in range(1, 5):
season_power = city_data[city_data['season'] == s]['power_output']
seasonal_data.extend([(city, seasons[s-1], p) for p in season_power])
season_df = pd.DataFrame(seasonal_data, columns=['City', 'Season', 'Power'])
for season in seasons:
season_values = season_df[
(season_df['City'] == city) &
(season_df['Season'] == season)
]['Power']
fig.add_trace(
go.Box(
y=season_values,
name=f'{city}-{season}',
marker_color=colors[i],
showlegend=False
),
row=2, col=2
)
# 5. Ramp Rate Histogram
all_ramps = []
for city in cities:
ramps = solar_data_all[city]['power_output'].diff().dropna()
all_ramps.extend(ramps.values)
fig.add_trace(
go.Histogram(
x=all_ramps,
nbinsx=50,
name='Ramp Rates',
marker_color='lightblue',
showlegend=False
),
row=3, col=1
)
# 6. Cloud Impact
for i, city in enumerate(cities):
cloud_data = solar_data_all[city].groupby(
pd.cut(solar_data_all[city]['cloud_impact'],
bins=[0, 0.3, 0.6, 0.9, 1.0])
)['power_output'].mean()
fig.add_trace(
go.Scatter(
x=['Heavy Cloud', 'Moderate Cloud', 'Light Cloud', 'Clear'],
y=cloud_data.values,
name=city,
line=dict(color=colors[i], width=2),
mode='lines+markers',
showlegend=False
),
row=3, col=2
)
# Update layout
fig.update_layout(
height=1200,
title_text="Solar Generation Dashboard: 6 Cities, 3 Continents",
title_font_size=20,
showlegend=True,
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1
)
)
# Update axes
fig.update_xaxes(title_text="City", row=1, col=1)
fig.update_yaxes(title_text="Capacity Factor (%)", row=1, col=1)
fig.update_xaxes(title_text="Month", row=1, col=2)
fig.update_yaxes(title_text="Average Power (MW)", row=1, col=2)
fig.update_xaxes(title_text="Hour of Day", row=2, col=1)
fig.update_yaxes(title_text="Average Power (MW)", row=2, col=1)
fig.update_xaxes(title_text="Season", row=2, col=2)
fig.update_yaxes(title_text="Power (MW)", row=2, col=2)
fig.update_xaxes(title_text="Ramp Rate (MW/hour)", row=3, col=1)
fig.update_yaxes(title_text="Frequency", row=3, col=1)
fig.update_xaxes(title_text="Cloud Condition", row=3, col=2)
fig.update_yaxes(title_text="Average Power (MW)", row=3, col=2)
return fig
# Create and display dashboard
print("\n📊 Creating interactive dashboard...")
dashboard = create_dashboard()
dashboard.show()
# Also create individual detailed plots
def create_detailed_comparison():
"""Create detailed comparison plots"""
# Capacity factor heatmap
cf_matrix = []
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
for city in LOCATIONS.keys():
monthly_cf = []
for month in range(1, 13):
month_data = solar_data_all[city][solar_data_all[city].index.month == month]
cf = month_data['power_output'].mean() / 100 * 100 # Convert to percentage
monthly_cf.append(cf)
cf_matrix.append(monthly_cf)
fig_heatmap = go.Figure(data=go.Heatmap(
z=cf_matrix,
x=months,
y=list(LOCATIONS.keys()),
colorscale='RdYlBu',
text=[[f'{val:.1f}%' for val in row] for row in cf_matrix],
texttemplate='%{text}',
textfont={"size": 10},
colorbar=dict(title="Capacity Factor (%)")
))
fig_heatmap.update_layout(
title="Monthly Capacity Factor Heatmap",
xaxis_title="Month",
yaxis_title="City",
height=400
)
return fig_heatmap
print("\n🗺️ Creating capacity factor heatmap...")
heatmap = create_detailed_comparison()
heatmap.show()
Step 6: Export Results
Let's save our analysis for future use:
def export_results():
"""
Export data and results for further analysis - fully dynamic version
"""
# Sort cities by various metrics for dynamic reporting
sorted_by_cf = sorted(all_metrics.items(),
key=lambda x: x[1]['annual_capacity_factor'],
reverse=True)
sorted_by_variability = sorted(all_metrics.items(),
key=lambda x: x[1]['variability_score'])
sorted_by_seasonal = sorted(all_metrics.items(),
key=lambda x: x[1]['seasonal_ratio'],
reverse=True)
# Get best and worst dynamically
best_city = sorted_by_cf[0][0]
worst_city = sorted_by_cf[-1][0]
most_stable = sorted_by_variability[0][0]
most_variable = sorted_by_variability[-1][0]
most_seasonal = sorted_by_seasonal[0][0]
least_seasonal = sorted_by_seasonal[-1][0]
# Define thresholds for recommendations
high_cf_threshold = 25.0 # %
low_cf_threshold = 15.0 # %
high_variability_threshold = 20.0 # MW/hour
high_seasonal_threshold = 2.0 # ratio
# Categorize cities based on performance
excellent_solar = [city for city, metrics in all_metrics.items()
if metrics['annual_capacity_factor'] * 100 > high_cf_threshold]
poor_solar = [city for city, metrics in all_metrics.items()
if metrics['annual_capacity_factor'] * 100 < low_cf_threshold]
high_variability = [city for city, metrics in all_metrics.items()
if metrics['variability_score'] > high_variability_threshold]
high_seasonal = [city for city, metrics in all_metrics.items()
if metrics['seasonal_ratio'] > high_seasonal_threshold]
# Create summary report with dynamic content
report = f"""
SOLAR RESOURCE ANALYSIS REPORT
Generated: {datetime.now().strftime('%Y-%m-%d %H:%M')}
EXECUTIVE SUMMARY
================
Best Location: {best_city}
- Annual Capacity Factor: {all_metrics[best_city]['annual_capacity_factor']*100:.1f}%
- Peak Sun Hours: {all_metrics[best_city]['peak_sun_hours']:.1f} hours/day
- Best Month: Month {all_metrics[best_city]['best_month']} ({all_metrics[best_city]['best_month_cf']*100:.1f}% CF)
- Worst Month: Month {all_metrics[best_city]['worst_month']} ({all_metrics[best_city]['worst_month_cf']*100:.1f}% CF)
Most Challenging Location: {worst_city}
- Annual Capacity Factor: {all_metrics[worst_city]['annual_capacity_factor']*100:.1f}%
- Peak Sun Hours: {all_metrics[worst_city]['peak_sun_hours']:.1f} hours/day
- Seasonal Ratio: {all_metrics[worst_city]['seasonal_ratio']:.1f}x (summer/winter)
PERFORMANCE RANKINGS
===================
By Annual Capacity Factor:
{chr(10).join(f" {i+1}. {city}: {metrics['annual_capacity_factor']*100:.1f}%"
for i, (city, metrics) in enumerate(sorted_by_cf))}
By Generation Stability (least variable first):
{chr(10).join(f" {i+1}. {city}: {metrics['variability_score']:.1f} MW/hour"
for i, (city, metrics) in enumerate(sorted_by_variability))}
KEY INSIGHTS
============
1. Geographic Patterns:
- Best performing region: {', '.join(excellent_solar) if excellent_solar else 'None above ' + str(high_cf_threshold) + '%'}
- Challenging locations: {', '.join(poor_solar) if poor_solar else 'None below ' + str(low_cf_threshold) + '%'}
- Performance spread: {(sorted_by_cf[0][1]['annual_capacity_factor'] - sorted_by_cf[-1][1]['annual_capacity_factor'])*100:.1f} percentage points
2. Latitude Impact:
- Highest latitude analyzed: {max(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[0]} ({max(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[1]['lat']:.1f}°)
- Equatorial location: {min(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[0]} ({min(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[1]['lat']:.1f}°)
- Performance difference: {abs(all_metrics[max(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[0]]['annual_capacity_factor'] - all_metrics[min(LOCATIONS.items(), key=lambda x: abs(x[1]['lat']))[0]]['annual_capacity_factor'])*100:.1f} percentage points
3. Climate Effects:
{chr(10).join(f" - {city} ({LOCATIONS[city]['climate']}): {metrics['annual_capacity_factor']*100:.1f}% CF"
for city, metrics in sorted_by_cf[:6])}
4. Variability Analysis:
- Most stable generation: {most_stable} ({all_metrics[most_stable]['variability_score']:.1f} MW/hour)
- Highest variability: {most_variable} ({all_metrics[most_variable]['variability_score']:.1f} MW/hour)
- High variability locations (>{high_variability_threshold} MW/hour): {', '.join(high_variability) if high_variability else 'None'}
5. Seasonal Patterns:
- Strongest seasonality: {most_seasonal} ({all_metrics[most_seasonal]['seasonal_ratio']:.1f}x summer/winter)
- Most consistent: {least_seasonal} ({all_metrics[least_seasonal]['seasonal_ratio']:.1f}x summer/winter)
- Locations with >2x seasonal variation: {', '.join(high_seasonal) if high_seasonal else 'None'}
RECOMMENDATIONS
==============
1. Utility-Scale Development:
{' - Prioritize: ' + ', '.join(excellent_solar) + ' (>' + str(high_cf_threshold) + '% CF)' if excellent_solar else ' - No locations exceed ' + str(high_cf_threshold) + '% CF threshold'}
{' - Avoid: ' + ', '.join(poor_solar) + ' (<' + str(low_cf_threshold) + '% CF)' if poor_solar else ' - All locations exceed ' + str(low_cf_threshold) + '% CF minimum'}
2. Storage Requirements:
{' - Minimal storage needed: ' + most_stable if all_metrics[most_stable]['variability_score'] < 15 else ' - All locations require significant storage'}
{' - Maximum storage needed: ' + ', '.join(high_variability) if high_variability else ' - No locations have extreme variability'}
3. Seasonal Considerations:
{' - Year-round generation: ' + least_seasonal + f' ({all_metrics[least_seasonal]["seasonal_ratio"]:.1f}x ratio)'}
{' - Strong winter backup needed: ' + ', '.join(high_seasonal) if high_seasonal else ' - No locations have extreme seasonality'}
4. Economic Viability (at $30/MWh):
{chr(10).join(f" - {city}: ${metrics['annual_capacity_factor']*100*8760*30:,.0f}/MW/year"
for city, metrics in sorted_by_cf[:3])}
TECHNICAL PARAMETERS USED
========================
- System capacity: 100 MW (reference)
- Panel type: Standard silicon (0.4%/°C temp coefficient)
- Mounting: Fixed horizontal (not optimized)
- Analysis period: Full year hourly (8,760 hours)
- Cloud model: Statistical (climate-based)
"""
# Save report
with open('solar_analysis_report.txt', 'w') as f:
f.write(report)
# Export metrics to CSV
metrics_export = pd.DataFrame(all_metrics).T
metrics_export.to_csv('solar_metrics_by_city.csv')
# Create downloadable data sample
sample_data = {}
for city in LOCATIONS.keys():
# Get one week in June as sample
june_week = solar_data_all[city][
(solar_data_all[city].index.month == 6) &
(solar_data_all[city].index.day <= 7)
][['ghi_actual', 'power_output', 'cloud_impact']].copy()
# Remove timezone information for Excel compatibility
june_week.index = june_week.index.tz_localize(None)
sample_data[city] = june_week
# Save sample data
with pd.ExcelWriter('solar_data_samples.xlsx') as writer:
for city, data in sample_data.items():
data.to_excel(writer, sheet_name=city)
# Create a summary statistics file
summary_stats = {
'analysis_date': datetime.now().strftime('%Y-%m-%d'),
'locations_analyzed': len(LOCATIONS),
'best_location': best_city,
'worst_location': worst_city,
'average_cf_all_locations': np.mean([m['annual_capacity_factor'] for m in all_metrics.values()]) * 100,
'cf_range': (sorted_by_cf[0][1]['annual_capacity_factor'] - sorted_by_cf[-1][1]['annual_capacity_factor']) * 100,
'total_cities_above_25cf': len(excellent_solar),
'total_cities_below_15cf': len(poor_solar)
}
with open('analysis_summary.json', 'w') as f:
import json
json.dump(summary_stats, f, indent=2)
print("📁 Files exported:")
print(" - solar_analysis_report.txt (Full report)")
print(" - solar_metrics_by_city.csv (All metrics)")
print(" - solar_data_samples.xlsx (Sample hourly data)")
print(" - analysis_summary.json (Summary statistics)")
# Print dynamic summary
print(f"\n📊 Analysis Summary:")
print(f" - Best location: {best_city} ({all_metrics[best_city]['annual_capacity_factor']*100:.1f}% CF)")
print(f" - Most challenging: {worst_city} ({all_metrics[worst_city]['annual_capacity_factor']*100:.1f}% CF)")
print(f" - Average CF across all locations: {summary_stats['average_cf_all_locations']:.1f}%")
print(f" - Locations suitable for utility-scale (>25% CF): {len(excellent_solar)}")
return report
# Export everything
print("\n💾 Exporting results...")
report = export_results()
# Show first 1000 characters of report
print("\n📋 Report Preview (first 1000 characters):")
print(report[:1000] + "\n...")
# Create a function to visualize the summary
def create_summary_visualization():
"""Create a summary infographic of results"""
fig, ax = plt.subplots(figsize=(12, 8))
ax.axis('off')
# Title
ax.text(0.5, 0.95, 'Solar Resource Analysis Summary',
fontsize=20, fontweight='bold', ha='center')
# Get sorted data
sorted_cities = sorted(all_metrics.items(),
key=lambda x: x[1]['annual_capacity_factor'],
reverse=True)
# Create visual summary
y_pos = 0.85
for i, (city, metrics) in enumerate(sorted_cities):
cf = metrics['annual_capacity_factor'] * 100
color = colors[i % len(colors)]
# City name and bar
ax.text(0.1, y_pos, f"{city}:", fontsize=12, fontweight='bold')
ax.barh(y_pos, cf/100 * 0.6, height=0.03, left=0.25, color=color, alpha=0.7)
ax.text(0.25 + cf/100 * 0.6 + 0.01, y_pos, f"{cf:.1f}%",
fontsize=10, va='center')
# Additional info
ax.text(0.92, y_pos, f"{metrics['peak_sun_hours']:.1f} PSH",
fontsize=9, ha='right', color='gray')
y_pos -= 0.12
# Add legend
ax.text(0.1, 0.15, "CF = Capacity Factor", fontsize=9, style='italic')
ax.text(0.1, 0.10, "PSH = Peak Sun Hours/day", fontsize=9, style='italic')
# Add key insight
best = sorted_cities[0]
worst = sorted_cities[-1]
ax.text(0.5, 0.05,
f"Best: {best[0]} ({best[1]['annual_capacity_factor']*100:.1f}%) | "
f"Most Challenging: {worst[0]} ({worst[1]['annual_capacity_factor']*100:.1f}%)",
fontsize=11, ha='center', bbox=dict(boxstyle="round,pad=0.3",
facecolor="lightgray", alpha=0.5))
plt.tight_layout()
plt.savefig('solar_analysis_summary_infographic.png', dpi=300, bbox_inches='tight')
plt.show()
print("\n📊 Creating summary visualization...")
create_summary_visualization()
Step 7: Key Insights and Visualizations
Let's create some final visualizations that tell the story:
# Create publication-quality comparison chart
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 1. Capacity Factor Comparison
ax1 = axes[0, 0]
cities_sorted = sorted(LOCATIONS.keys(),
key=lambda x: all_metrics[x]['annual_capacity_factor'],
reverse=True)
cfs = [all_metrics[city]['annual_capacity_factor']*100 for city in cities_sorted]
bars = ax1.bar(cities_sorted, cfs, color=colors)
ax1.set_ylabel('Annual Capacity Factor (%)', fontsize=12)
ax1.set_title('A. Solar Capacity Factors Across Cities', fontsize=14, fontweight='bold')
ax1.grid(axis='y', alpha=0.3)
# Add value labels
for bar, cf in zip(bars, cfs):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{cf:.1f}%', ha='center', va='bottom')
# 2. Daily Profile Comparison (Summer Solstice)
ax2 = axes[0, 1]
for i, city in enumerate(cities_sorted[:4]): # Top 4 cities
june_data = solar_data_all[city][
(solar_data_all[city].index.month == 6) &
(solar_data_all[city].index.day == 21)
]
ax2.plot(june_data.index.hour, june_data['power_output'],
label=city, color=colors[i], linewidth=2)
ax2.set_xlabel('Hour of Day', fontsize=12)
ax2.set_ylabel('Power Output (MW)', fontsize=12)
ax2.set_title('B. Summer Solstice Generation Profiles', fontsize=14, fontweight='bold')
ax2.legend()
ax2.grid(alpha=0.3)
# 3. Seasonal Variation
ax3 = axes[1, 0]
seasonal_ratios = [all_metrics[city]['seasonal_ratio'] for city in cities_sorted]
bars = ax3.bar(cities_sorted, seasonal_ratios, color=colors)
ax3.set_ylabel('Summer/Winter Ratio', fontsize=12)
ax3.set_title('C. Seasonal Variation (Summer/Winter Output)', fontsize=14, fontweight='bold')
ax3.axhline(y=1, color='red', linestyle='--', alpha=0.5)
ax3.grid(axis='y', alpha=0.3)
# 4. Variability vs Capacity Factor
ax4 = axes[1, 1]
x_cf = [all_metrics[city]['annual_capacity_factor']*100 for city in LOCATIONS.keys()]
y_var = [all_metrics[city]['variability_score'] for city in LOCATIONS.keys()]
scatter = ax4.scatter(x_cf, y_var, s=200, c=colors[:len(LOCATIONS)], alpha=0.7, edgecolors='black')
for i, city in enumerate(LOCATIONS.keys()):
ax4.annotate(city, (x_cf[i], y_var[i]), xytext=(5, 5),
textcoords='offset points', fontsize=10)
ax4.set_xlabel('Annual Capacity Factor (%)', fontsize=12)
ax4.set_ylabel('Variability Score (MW/hour)', fontsize=12)
ax4.set_title('D. Capacity Factor vs Generation Variability', fontsize=14, fontweight='bold')
ax4.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('solar_analysis_summary.png', dpi=300, bbox_inches='tight')
plt.show()
# Create insight summary
print("\n🔍 KEY INSIGHTS FROM THE ANALYSIS:")
print("="*50)
print("\n1. LATITUDE EFFECTS:")
print(f" - Every 10° increase in latitude ≈ 3-4% decrease in capacity factor")
print(f" - Oslo (60°N) generates {(1 - all_metrics['Oslo']['annual_capacity_factor']/all_metrics['Cairo']['annual_capacity_factor'])*100:.0f}% less than Cairo (30°N)")
print("\n2. CLIMATE IMPACTS:")
desert_cf = all_metrics['Cairo']['annual_capacity_factor']
oceanic_cf = all_metrics['London']['annual_capacity_factor']
print(f" - Desert climates outperform oceanic by {(desert_cf/oceanic_cf - 1)*100:.0f}%")
print(f" - Cloud cover is the dominant factor, not temperature")
print("\n3. ECONOMIC IMPLICATIONS:")
print(f" - At $30/MWh, Cairo generates ${all_metrics['Cairo']['annual_capacity_factor']*100*8760*30:,.0f}/MW/year")
print(f" - London only generates ${all_metrics['London']['annual_capacity_factor']*100*8760*30:,.0f}/MW/year")
print(f" - Same panels, {(all_metrics['Cairo']['annual_capacity_factor']/all_metrics['London']['annual_capacity_factor'] - 1)*100:.0f}% more revenue in Cairo")
print("\n4. GRID INTEGRATION CHALLENGES:")
max_var_city = max(all_metrics.items(), key=lambda x: x[1]['variability_score'])[0]
min_var_city = min(all_metrics.items(), key=lambda x: x[1]['variability_score'])[0]
print(f" - {max_var_city} has highest variability (harder grid integration)")
print(f" - {min_var_city} has smoothest generation profile")
print(f" - Variability doesn't correlate with capacity factor!")
What Did We Learn?
This dashboard reveals several crucial insights:
Location is Everything: Cairo's 29.5% capacity factor vs Oslo's 11.2% shows why "solar works everywhere" is technically true but economically questionable.
Seasonality Varies Wildly: Cape Town's 3.5x summer/winter ratio means you need massive winter backup. Nairobi's 1.2x ratio near the equator is much more manageable.
Clouds > Temperature: London's problem isn't being cold—it's being cloudy. Desert locations win not because they're hot, but because they're clear.
Variability ≠ Low Capacity: Some high-performing locations (like Cape Town) have high variability due to weather patterns. This affects storage sizing.
Your Turn: Customize the Dashboard
Now you have a working solar analysis tool! Here's how to adapt it:
Add Your City:
LOCATIONS['Your_City'] = {
'lat': your_latitude,
'lon': your_longitude,
'tz': 'Your/Timezone',
'country': 'Your Country',
'climate': 'Climate type',
'challenge': 'Main solar challenge'
}
Change the Analysis Period:
Modify
year=2023to analyze different yearsAdjust the date ranges for seasonal studies
Add Economic Analysis:
Input local electricity prices
Calculate revenue projections
Compare to diesel generation costs
Integrate Real Weather Data:
Use APIs from OpenWeatherMap or similar
Import historical cloud cover data
Validate against actual solar farm output
Next Steps
You now have:
✅ A working solar analysis dashboard
✅ Capacity factors for 6 diverse cities
✅ Understanding of why location matters
✅ Code you can modify and extend
But this is just solar in isolation. Real energy systems need reliability. Next few weeks, we'll explore why biomass might be the perfect partner for solar—turning agricultural waste into the missing piece of the renewable puzzle.
Until then, try the dashboard with your own location. Share your results in the comments. Let's build a global picture of solar reality, one city at a time.
Next: "The Biomass Paradox: Why We're Literally Burning Money in Fields"—including why rice husks might be more valuable than rice.
Resources:
Questions? Found interesting patterns in your city? Drop a comment below or reach out on Twitter/Threads @kaykluz



